引言:
在人工智能领域持续创新的推动下,复旦大学最近发布了一个引人注目的开源项目——EMO。这一技术通过输入音频让静态的面部照片变得生动,配以自然的表情和动作,为多媒体内容创作提供了全新的可能性。
EMO 项目介绍:
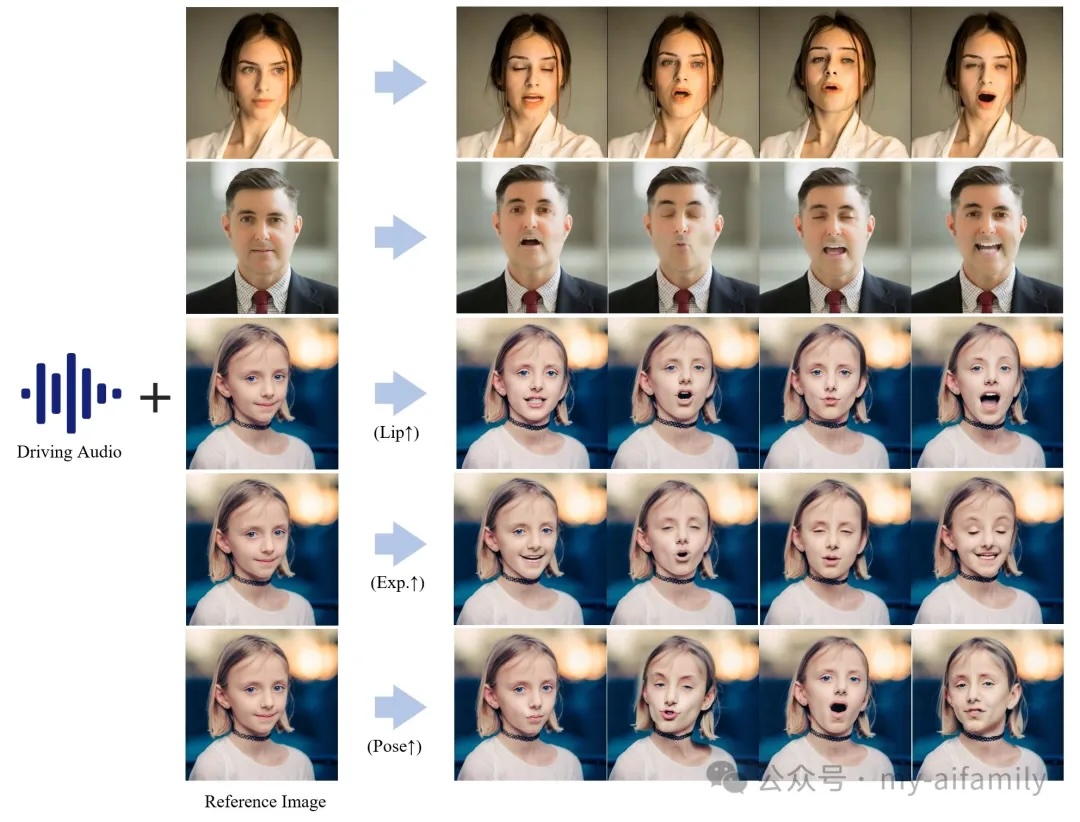
EMO 利用先进的端到端扩散范式,结合了音频与视觉合成的技术,使得照片可以根据音频输入做出对应的表情和唇动。这种技术不仅提高了视觉输出与音频输入之间的同步精度,也在自然性和真实感上设立了新的标准。
技术细节:
EMO 项目的核心在于其分层音频驱动的视觉合成模块,这一模块允许对表情和姿势进行精细的控制。与传统的音视频同步技术相比,EMO 在处理唇部同步、表情变化及头部姿态调整方面具有更高的精度和适应性。
现有产品比对:
相比如 Deepfake 或 Adobe Character Animator 等现有产品,EMO 提供了更加精确和个性化的控制。例如,Deepfake 主要用于面部换脸,而 EMO 能够维持原有身份的特征,更专注于表达和动作的真实性。Adobe的产品虽然也支持音频驱动的动画制作,但 EMO 在实时性和自然度上具有明显优势,特别是在处理非标准化输入如方言或特殊口音时的适应能力。
应用场景:
EMO 的应用场景广泛,从电影和游戏行业的角色动画到在线教育的虚拟讲师,再到社交媒体上个性化的视频内容创作。每一个领域都能从这种高度逼真的音频驱动视觉合成技术中受益。
市场和未来展望:
随着多媒体内容消费的增加和用户对互动性及个性化内容需求的提升,EMO 类技术的市场前景看好。未来,这种技术可能进一步扩展到虚拟现实和增强现实,为用户提供更加丰富和沉浸式的体验。
结语:
复旦大学的 EMO 项目不仅展示了 AI 在视觉和音频合成领域的强大潜力,也预示着未来人机交互方式的深刻变革。随着技术的不断进步和应用的不断拓展,我们有理由期待更多创新的出现。
项目地址:
https://fudan-generative-vision.github.io/hallo/#/
----------伟大的分割线-----------
AI饭米粒(my-aifamily) 由一群靠谱的人建立,在AI时代,希望能各位带来AI相关的知识
AI饭米粒只发原创或授权发表的文章,不转载网上的文章
所发的文章,均可找到原作者进行沟通。
投稿请联系:
shenzhe163@gmail.com
本文由 桶哥 授权 AI饭米粒 发布,转载请注明本来源信息和以下的二维码(长按可识别二维码关注)
